STM32 总线架构详解:ICode/DCode/System/DMA 工作原理
- 嵌入式开发
- 5小时前
- 16热度
- 0评论
STM32 总线架构采用改进型哈佛架构,CPU 通过 ICode、DCode、System 三条通路工作,DMA 也能作为主设备参与访问;AHB/APB 是片上总线分层,连接不同速率的外设。本文将从访问通路和片上互连两个层次,帮你建立清晰的认知。
改进型哈佛架构:为什么要多条总线
| 架构 | 特点 |
|---|---|
| 冯·诺依曼 | 指令和数据共享一条路,易瓶颈 |
| 经典哈佛 | 指令和数据分路,但结构死板 |
| STM32 改进型哈佛 | 统一编址 + 逻辑分路访问,兼顾灵活与效率 |
💡 核心特点:物理上统一编址,逻辑上分路访问。取指和取常量可以并行。
核心思想:把取指、取数据、访问外设、DMA 搬运尽量分路,减少冲突,提高效率。
核心思想:把取指、取数据、访问外设、DMA 搬运尽量分路,减少冲突,提高效率。
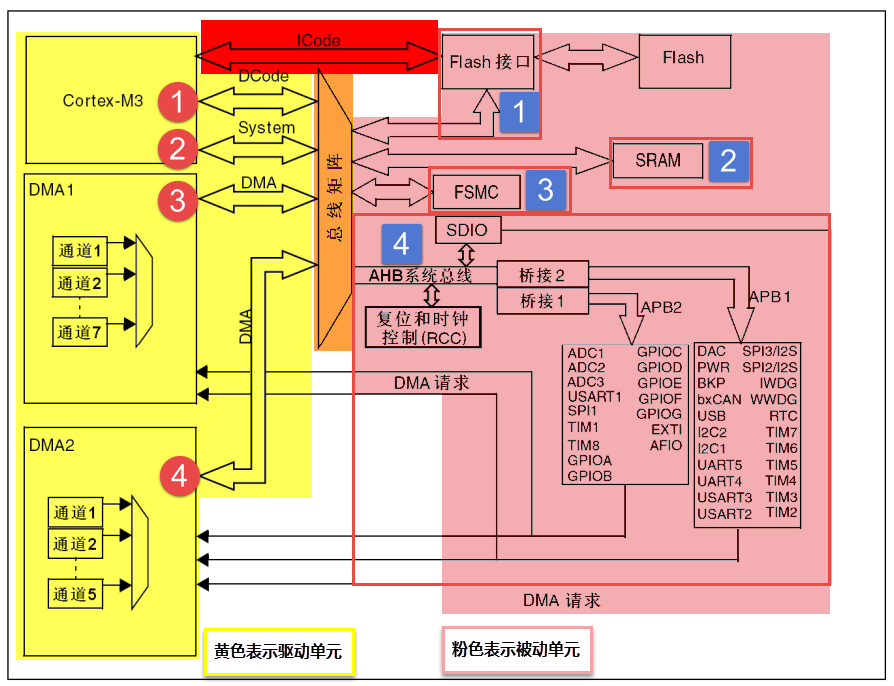
1. 总线架构
CPU
├─ ICode ──> Flash(取指令)
├─ DCode ──> Flash(取常量)
└─ System ──> SRAM / 外设 / 外部存储器
DMA
└─ DMA Bus ─> SRAM / 外设 / 外部存储器
BusMatrix 负责仲裁 CPU 和 DMA 的访问冲突
ℹ️ 两个层次:访问通路(ICode/DCode/System/DMA)指谁通过哪条路访问资源,片上互连(AHB/APB)指芯片内部总线怎么分层。每条总线由地址线+数据线+控制线组成,"32位总线"指数据线宽度。
1.1 驱动单元(主设备)
主设备主动发起读写。STM32 中只有两个主设备:CPU 和 DMA 控制器,它们通过不同的总线访问各种资源。
a) ICode 总线 — CPU 取指令
- ICode = Instruction Code,专门用来取指,几乎每时每刻都在使用
- 基于 AHB-Lite 32 位总线,负责地址
0x0000_0000 – 0x1FFF_FFFF范围的取指 - 取指以字(32位)为单位,即使是 16 位 Thumb 指令也如此 → 一次可取出两条 16 位指令
while(1) { led_toggle(); }→ CPU 不断从 Flash 取指,走 ICode
b) DCode 总线 — CPU 取数据
- DCode = Data Code,用来从 Flash 取数据(常量)
- 基于 AHB-Lite 32 位总线,负责地址
0x0000_0000 – 0x1FFF_FFFF范围的数据访问 - 仅支持对齐访问,不支持非对齐访问;也用于调试访问
const uint16_t table[] = {1,2,3,4};→ 读 table 走 DCode- 因为数据可以被 DCode 和 DMA 同时访问,需要经过 BusMatrix 仲裁
ℹ️ ICode vs DCode:两者访问同一地址段的 Flash,区别在于一个取指、一个取数据。Flash 接口处仲裁时,DCode 数据访问优先。
c) System 总线 — CPU 访问 SRAM 和外设
- 负责地址
0x2000_0000 – 0xDFFF_FFFF及0xE010_0000 – 0xFFFF_FFFF的所有传送 - 主要用于寄存器编程:读写 GPIO/USART/SPI 等外设寄存器,所有传送均为对齐访问
- 也负责对 Flash 的写操作(取指/取常量走 ICode/DCode,但写 Flash 走 System)
GPIOA->ODR ^= (1 << 5);→ 走 System 总线
d) DMA 总线 — DMA 控制器搬运数据
- DMA1 / DMA2 两个控制器,通过 AHB 总线接入系统
- 可搬运的数据来源:外设数据寄存器、SRAM、内部 Flash
- 外设↔内存、内存↔内存均可
- 因为数据可以被 DCode 和 DMA 同时访问,需要经过 BusMatrix 仲裁
- 核心价值:解放 CPU,不是"每次都更快"
1.2 被动单元(从设备)
从设备被动响应主设备的读写请求。
a) 内部 Flash(FLITF)
- 存放编译好的程序指令(.text)和只读数据(.rodata),F103 典型 64KB
- CPU 通过 ICode 总线取指令,通过 DCode 总线取常量
b) 内部 SRAM
- 程序的变量、堆栈等都在这里,F103 典型 20KB
- CPU 通过 System 总线访问,DMA 也可直接读写
c) FSMC
- Flexible Static Memory Controller,灵活的静态存储器控制器
- 仅大容量型号支持,可扩展外部 SRAM、NOR Flash、NAND Flash
⚠️ 注意:FSMC 只能扩展静态存储器(Static),不能扩展 SDRAM 等动态存储器。
d) AHB 到 APB 的桥
- 从 AHB 延伸出 APB2 和 APB1 两条总线
- 挂载 STM32 各种特色外设:GPIO、串口、I2C、SPI 等
- 这是学习 STM32 的重点 — 学会编程这些外设去驱动外部设备
1.3 BusMatrix — 片上交通调度器
- 仲裁算法:轮换(Round-Robin)
- 协调 4 个驱动端口(CPU 的 DCode、System,DMA1、DMA2)对 4 个被动端口(FLITF、SRAM、FSMC、AHB2APB 桥)的访问
- 访问目标不同 → 可并行(如 CPU 取指 + DMA 访问 SRAM)
- 访问目标相同 → 仲裁等待
1.4 AHB / APB 分层
CPU -> System Bus -> AHB -> AHB/APB Bridge -> APB 外设| 总线 | 定位 | 典型挂载 |
|---|---|---|
| AHB | 高速骨干 | DMA、RCC(时钟与复位控制器)、GPIO(部分系列)、USB、SDIO |
| APB1 | 低速外设 | UART(USART2~5)、SPI、I2C、基本TIM |
| APB2 | 较高速外设 | 高级TIM、ADC、USART1、部分GPIO |
⚠️ 注意:APB1 ≤ 36 MHz、APB2 ≤ 72 MHz 是 F1 系列的典型值,其他系列请查参考手册。
APB 位宽自动扩展:对 APB 寄存器进行 8 位或 16 位访问时,桥会自动将其转换为 32 位访问,无需软件干预。
2. Flash 与地址
2.1 Flash 等待与预取
- CPU 主频 > Flash 响应速度时,需插入 Wait State(配置
FLASH_ACR的LATENCY) - 预取缓冲区:共 2 个,每个 64 位,与 Flash 带宽一致,一次读 Flash 即可填满整个缓冲区
- 复位后自动开启
- CPU 每次取指最多 32 位;取当前指令时,下一条指令已在缓冲区等待
- 预取通过 ICode 完成;Flash 接口仲裁时 DCode 数据访问优先于 ICode 取指
⚠️ 常见误解:这不是"把代码整体搬到 SRAM 再执行",而是边取边缓冲。
2.2 地址映射速记
| 地址 | 区域 |
|---|---|
0x0800_0000 |
Flash(F103 典型 64KB) |
0x2000_0000 |
SRAM(F103 典型 20KB) |
0x4000_0000 |
APB1 外设 |
0x4001_0000 |
APB2 外设 |
0x4001_8000 |
AHB 外设 |
0xE000_0000 |
Cortex-M 内核私有外设 |
ℹ️ 以上为 F1 常见布局,具体以芯片参考手册为准。
启动映射机制
- 代码区始终从
0x0000_0000开始(通过 ICode 和 DCode 总线访问) - 数据区(SRAM)始终从
0x2000_0000开始(通过 System 总线访问) - Cortex-M3 CPU 始终从 ICode 总线获取复位向量(栈顶指针 + 复位处理函数地址),因此启动必须从代码区
0x0000_0000开始
💡 STM32 的启动灵活性
STM32F10xxx 实现了特殊的启动映射机制:通过 BOOT0/BOOT1 引脚配置,可以将 Flash(
STM32F10xxx 实现了特殊的启动映射机制:通过 BOOT0/BOOT1 引脚配置,可以将 Flash(
0x0800_0000)、系统存储器(0x1FFF_F000)或内置 SRAM(0x2000_0000)映射到代码区起始地址 0x0000_0000,从而实现从不同位置启动。
参考
- ARM Cortex-M3 / STM32 参考手册:总线架构与存储器映射章节
- https://github.com/Shikhargupta/MCU-Development-STM32/tree/master/Bus-interfaces#buses
- 6. 什么是寄存器 — [野火]STM32库开发实战指南——基于野火霸道开发板 文档